Private AI Consulting and Deployments
About
Research
Privacy
Book assessment
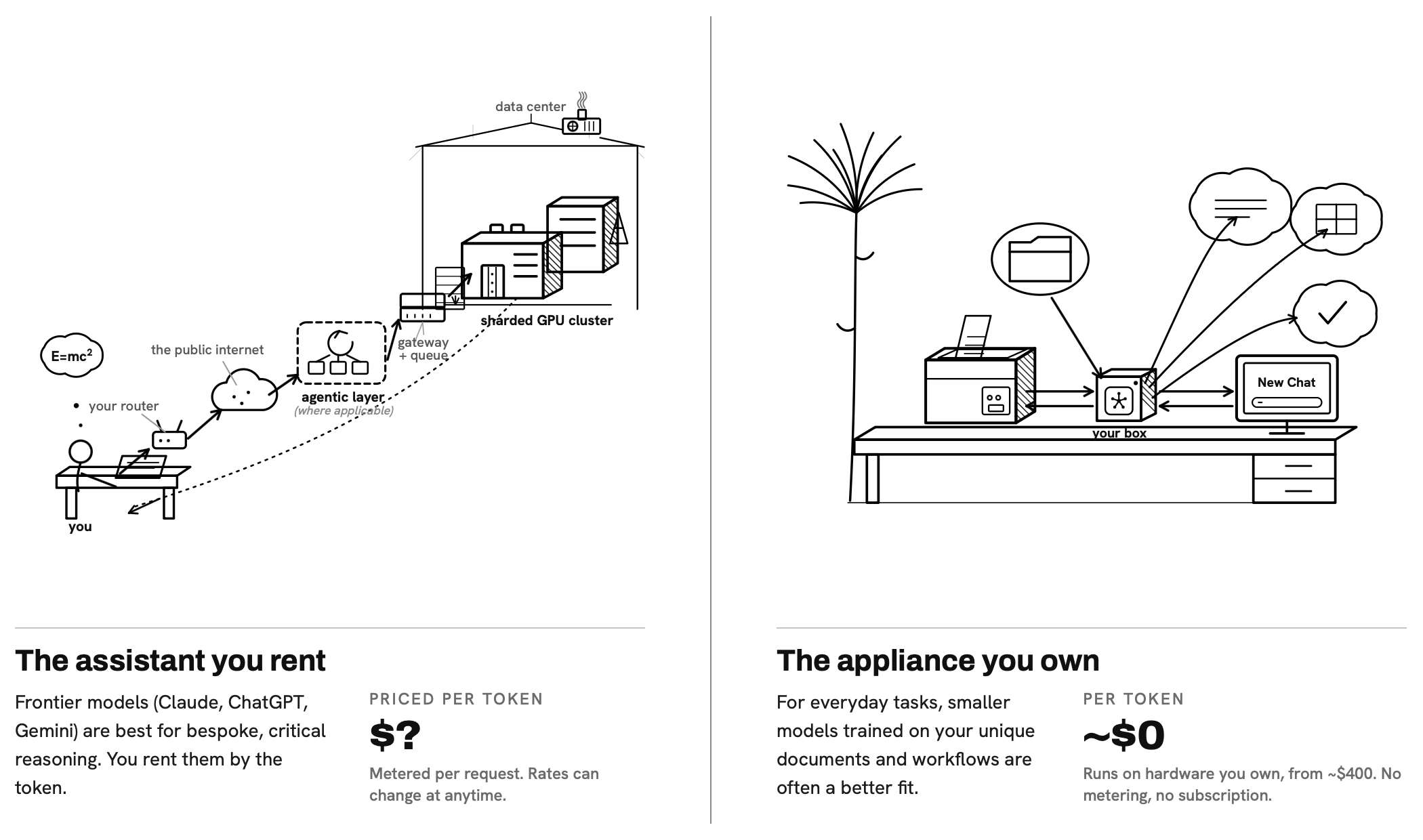
Where do your documents go when your office uses AI?
Book your free Private AI assessment
Phone
Video call
In person
Free · about 20 minutes · nothing to install